MMU-TLB基础知识
参考文献
最好的学习资料就是协议书,本文基于 ARM 官方的文档开展 MMU 的基础知识学习。
MMU 学习:learn_the_architecture_-_aarch64_memory_management_101811_0102_00_en.pdf
Arm® 架构参考手册:DDI0487H_a_a-profile_architecture_reference_manual.pdf
基本概念
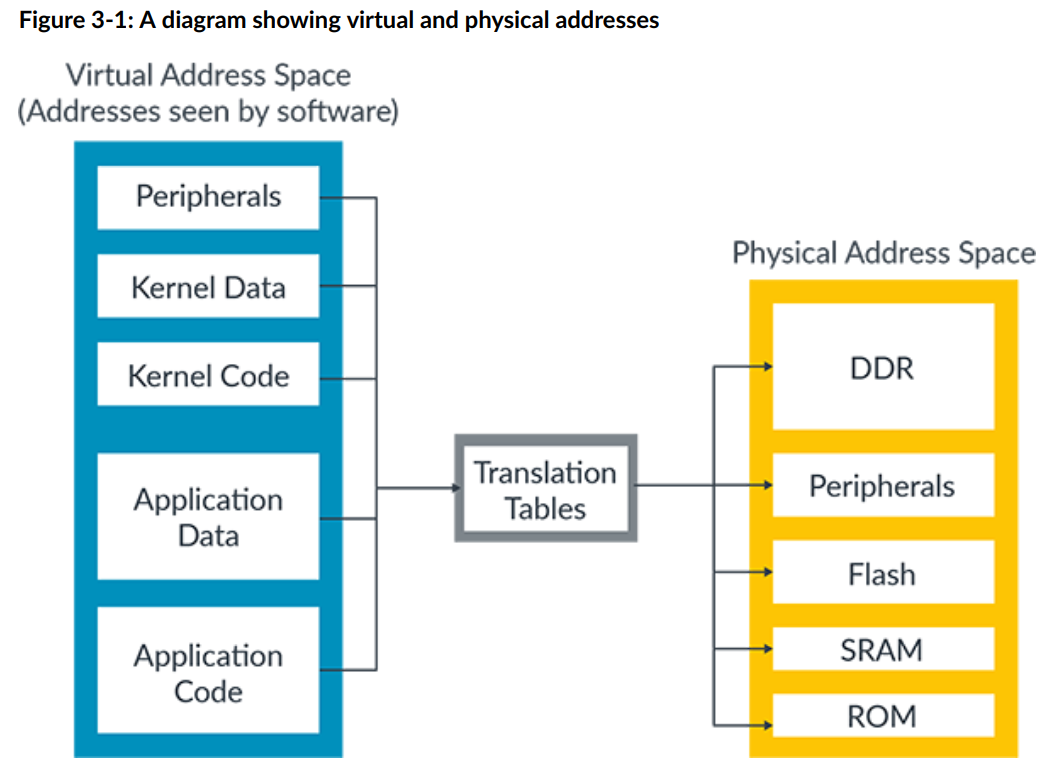
虚拟地址(VA,Virtual Address):处理器上运行的操作系统、应用程序所能看到的地址空间。虚拟地址并不真实存在于计算机中。
物理地址(PA,Physical Address):实际存储地址空间,如 DDR、Flash、SRAM 等实际存储数据的地方。
在处理器运行的过程中,需要将虚拟地址空间与物理地址空间进行转换,并对内存访问进行保护,即内存管理的主要工作。
虚拟地址通过映射转换为物理地址。虚拟地址和物理地址之间的映射存储在转换表(有时称为页表)。
使用虚拟地址的好处
- 使用虚拟地址的一个好处是,操作系统可以将零碎的物理地址空间拼接成连续的虚拟空间,供应用程序使用。连续的空间对于应用的运行而言当然是有好处的。
- 虚拟地址也有利于软件开发人员,他们在编写应用程序时不会也不需要知道系统的确切内存地址,由操作系统和硬件共同执行地址转换。
- 在实践中,每个应用程序都可以使用自己的一组虚拟地址,这些地址将映射到物理系统中的不同位置。当操作系统在不同的应用程序之间切换时,它会重新编程映射。
MMU 内存管理单元
内存管理单元 Memory Management Unit (MMU) , 负责将软件使用的虚拟地址转换为内存系统中使用的物理地址。
主要组成
包含以下内容:
- table walk unit 单元,它包含从内存中读取转换表的逻辑。
- Translation Lookaside Buffers (TLBs) ,用于缓存最近使用的转换内容。
软件发出的所有内存地址都是虚拟的。这些内存地址被传递到 MMU,MMU 会检查 TLB 中是否有最近使用的缓存转换。如果 MMU 找不到最近缓存的转换,则 table walk unit 将从内存中读取相应的 Table entry 表条目,如下所示:
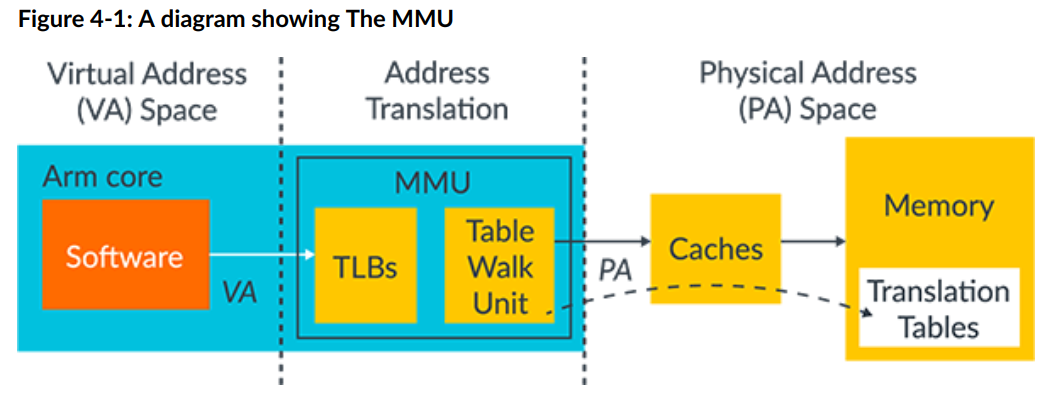
Table entry 表条目
转换表的工作原理是将虚拟地址空间划分为大小相等的块,并在表中为每个块提供一个 Table entry 表条目。
表中的条目 entry 0 提供 page 0 的映射,entry 1 提供 page 1 的映射,依此类推。每个条目都包含相应物理内存块的地址以及访问物理地址时要使用的属性。
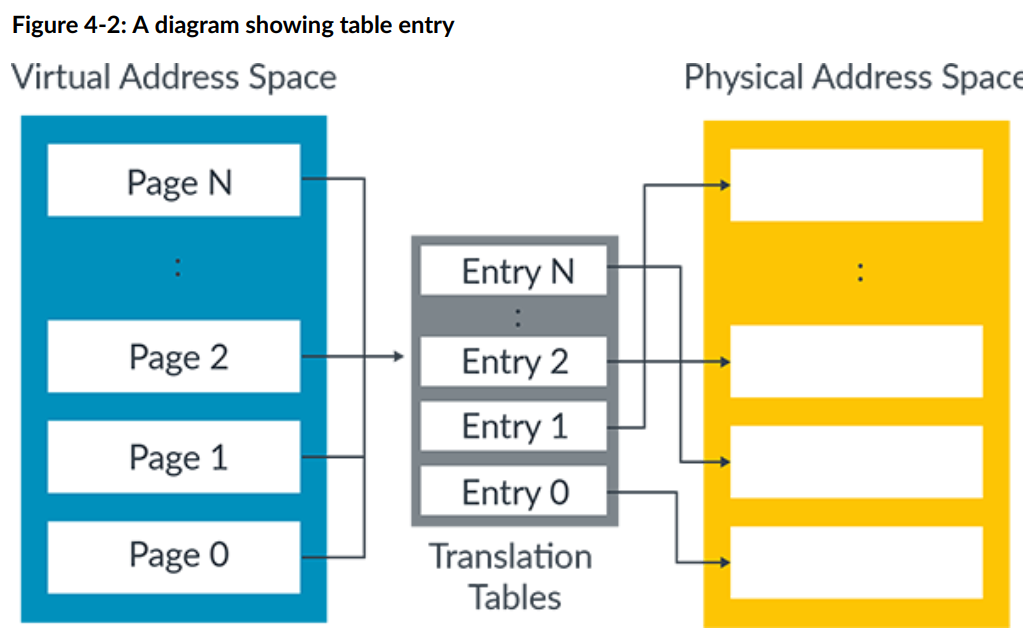
Table lookup 表查找
进行转换时,将进行表查找。当转换发生时,软件发出的虚拟地址被一分为二,如下图所示:
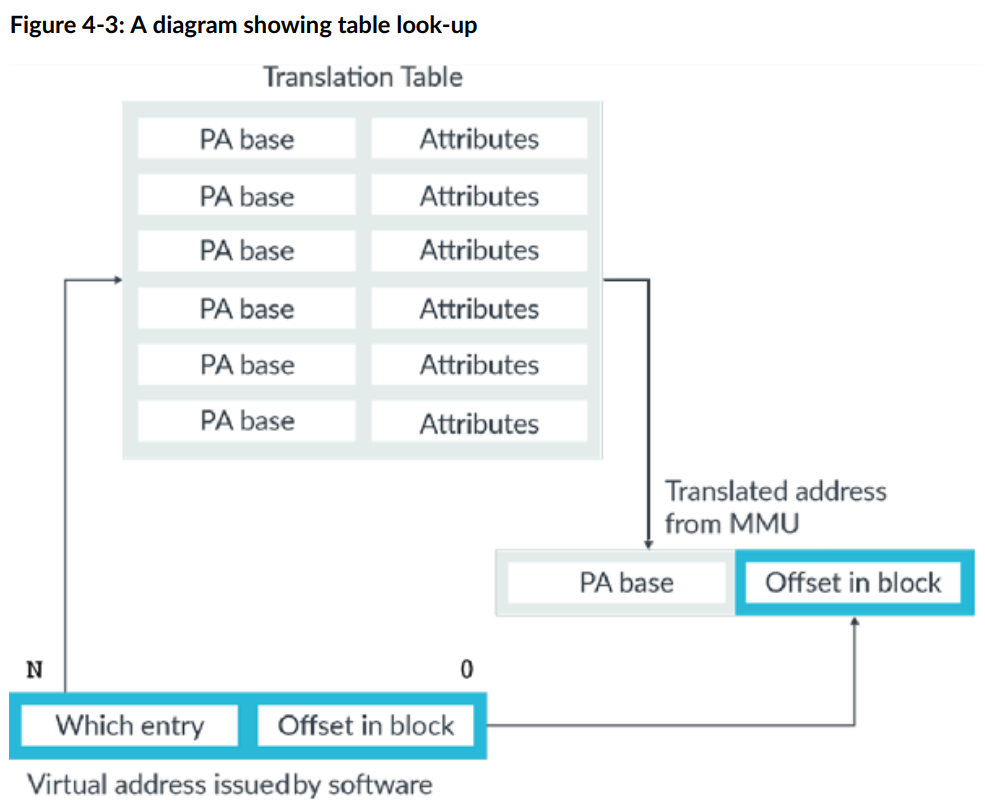
该图所展示的是一个单级表查找示例。
下方软件的虚拟地址分为两截:
upper-order bits 高位 bits 会告知,这是哪一个条目。基于该信息可以在 Translation Table 转换表中找到对应的 PA base 物理基地址以及内存属性。
lower-order bits 低位保有块偏移量信息,该信息并且不会因地址转换而发生任何改变。
最后将转换表中获得的物理基地址以及最开始就知晓的块偏移量相结合,得到最后的一个物理地址。
除了上述的单级查表之外,还有多级查表的形式(通常为 2 级)。第一个表(level 1 )将虚拟地址空间划分为大块。此表中的每个条目都可以指向大小相等的物理内存块,也可以指向另一个将该块细分为更小块的表。我们将这种类型的表称为“多级表”。在这里,我们可以看到一个具有三个级别的多级表的示例: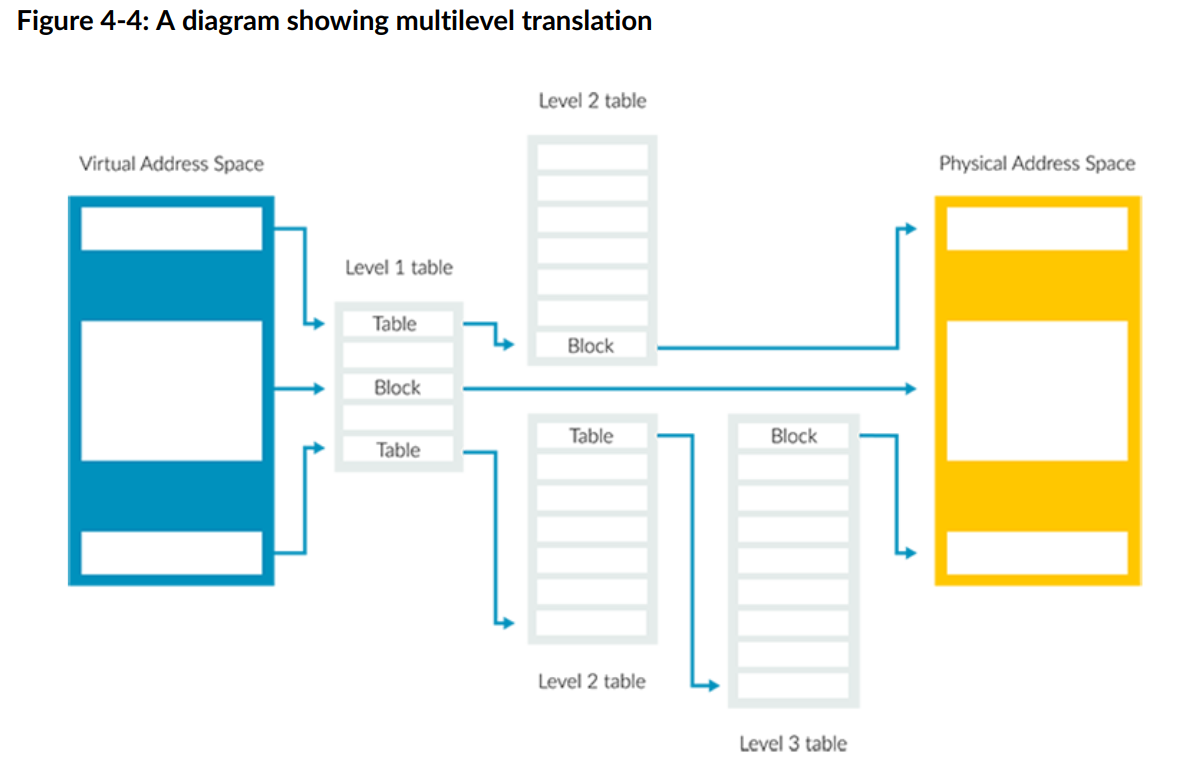
在 Armv8-A 架构中,最大级别数为 4,级别编号为 0 到 3。这种多级方法允许描述较大的块和较小的块。大块和小块的特征如下:
- 与小块相比,大块需要转换的读取级别更少。此外,大块在 TLB 中缓存的效率更高。
- 小块使软件能够对内存分配进行精细控制。但是,小块在 TLB 中缓存的效率较低,因为小块需要多次读取关卡才能转换。
为了管理这种权衡,操作系统必须在使用大块映射的效率与使用小块映射的灵活性之间取得平衡,以获得最佳性能。
TLB
TLB就是一个cache,俗称快表。
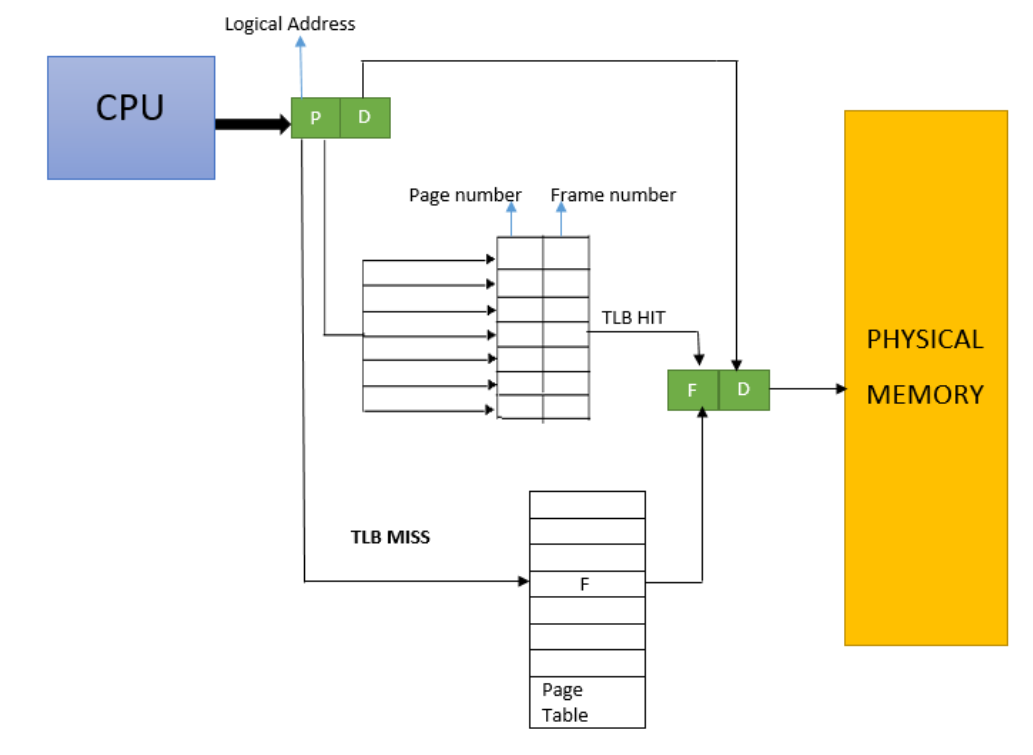
简单来讲,上面说了 MMU 会通过查表的方式将虚拟地址 VA 转化为物理地址 PA。但查表是要花时间的。一般来讲这个表是放在内存里,读内存是有比较大的代价的。
对于 CPU,通过给他添加 cache 来加快访问数据的速度。
Cache 存在的意义:根据局部性原理,对于当前访问的存储位置,接下来,它很可能会被多次访问(时间局部性),它的相邻位置也可能会被访问(空间局部性)。由于访问内存的速度远大于访问寄存器,所以在二者之间设置 cache,来暂存一部分指令或数据。
那么对于 MMU,TLB 就是它的 cache,用来加快查表的速度。
MMU 首先查询 TLB,发现有(hit),直接得到物理地址,在内存根据物理地址取数据。如果 TLB 没有这个虚拟地址(miss),那么就只能费力的通过页表来查找了。这个流程跟 cache 其实是一模一样的,当然,因为它本质就是一个 cache。
Address spaces 地址空间
空间结构
AArch64 中有几个独立的虚拟地址空间。下图显示了以下虚拟地址空间:
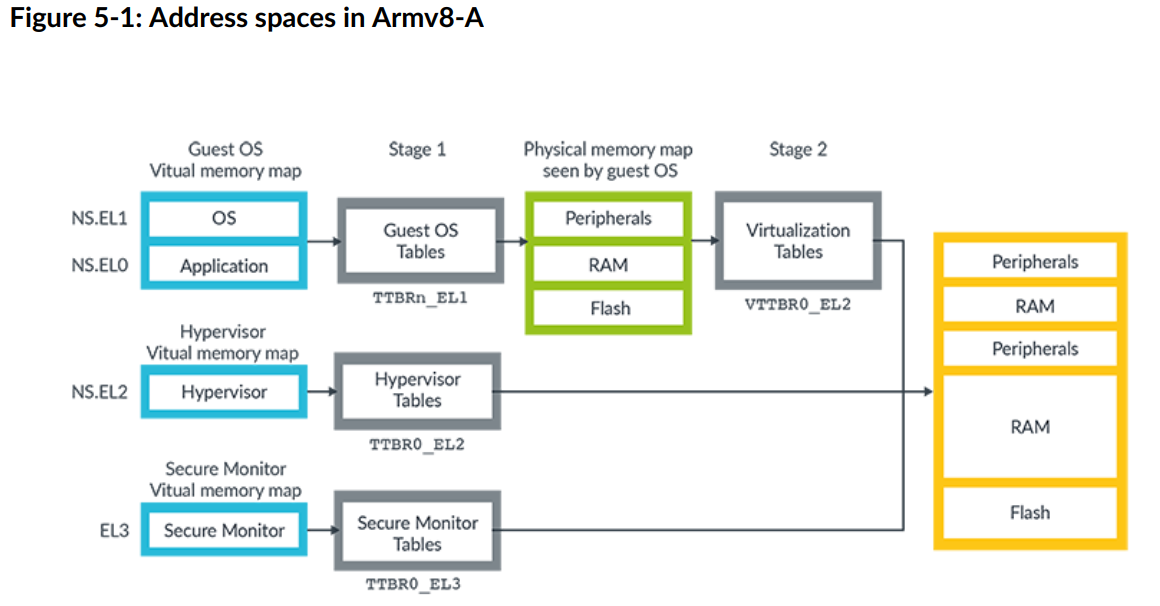
下图显示了三个虚拟地址空间:
- NS(Non-secure,不安全的) EL0 和 EL1。
- NS.EL2。
- EL3.
EL,Exception levels 异常级别。
ELn 中,随着 n 的增加,软件的执行权限也相应的增加;
EL0 被称为无特权执行;
EL2 提供了对虚拟化的支持
EL3 提供了安全状态切换功能(安全状态与非安装状态之间的切换)
由于存在多个虚拟地址空间,因此指定地址所在的地址空间非常重要。例如,NS。EL2:0x8000 是指非安全 EL2 虚拟地址空间中的地址 0x8000。
该图还显示,来自 NS.EL0 和 NS.EL1 的虚拟地址经过两组表(图中的 stage1 和 stage2)。这些表支持虚拟化,并允许 hypervisor 来管理虚拟机 (VM) 看到的物理地址空间。
在虚拟化中,我们将由操作系统控制的一组翻译称为第 1 阶段。阶段 1 表将虚拟地址转换为中间物理地址 (IPA)。在第 1 阶段,操作系统认为 IPA 是物理地址空间。但是,虚拟机管理程序控制第二组翻译,我们称之为阶段 2。第二组转换将 IPA 转换为物理地址。下图显示了两组翻译的工作原理:
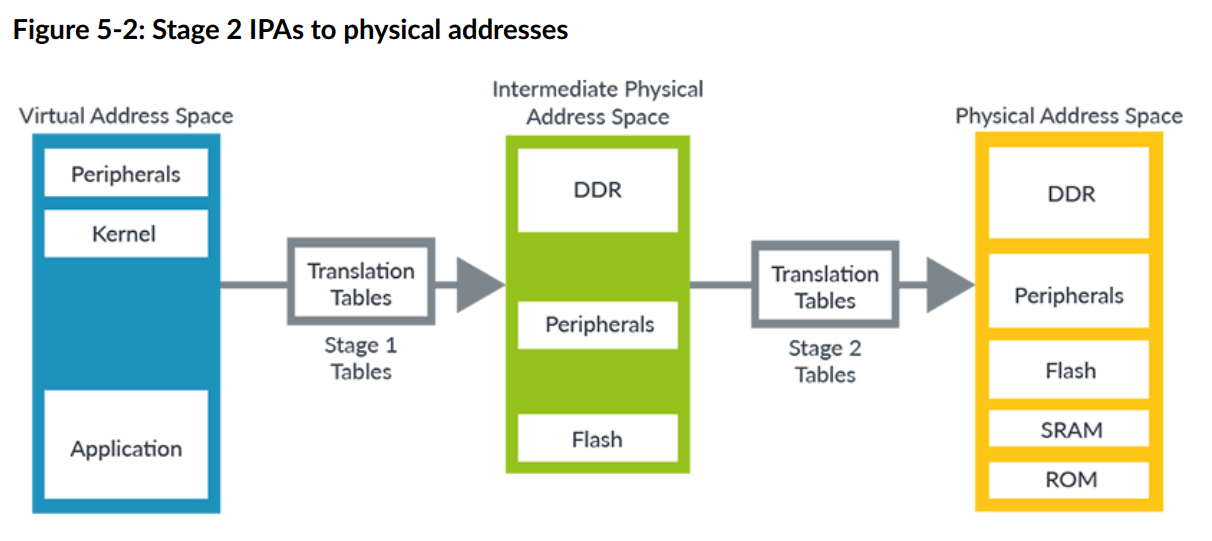
官方文档这里的表述可能有点绕,补充一点个人理解:
之前我们讨论的是,操作系统或者应用程序的虚拟地址 VA 转换为物理地址 PA 对吧。
那么,如果此时还存在一个虚拟机(虚拟机可以理解为一种应用程序,该应用程序模拟了一台计算机),那么虚拟机这么一台计算机,是不是也会拥有一个“虚拟机的物理地址”,这就是中间物理地址 IPA。在虚拟机运行的应用程序,将“虚拟机的虚拟地址”转化为“虚拟机的物理地址”,这个“虚拟机的物理地址”,还需要再转化为“实体机的物理地址”,即 VA->IPA->PA 整个流程的意思。
空间大小
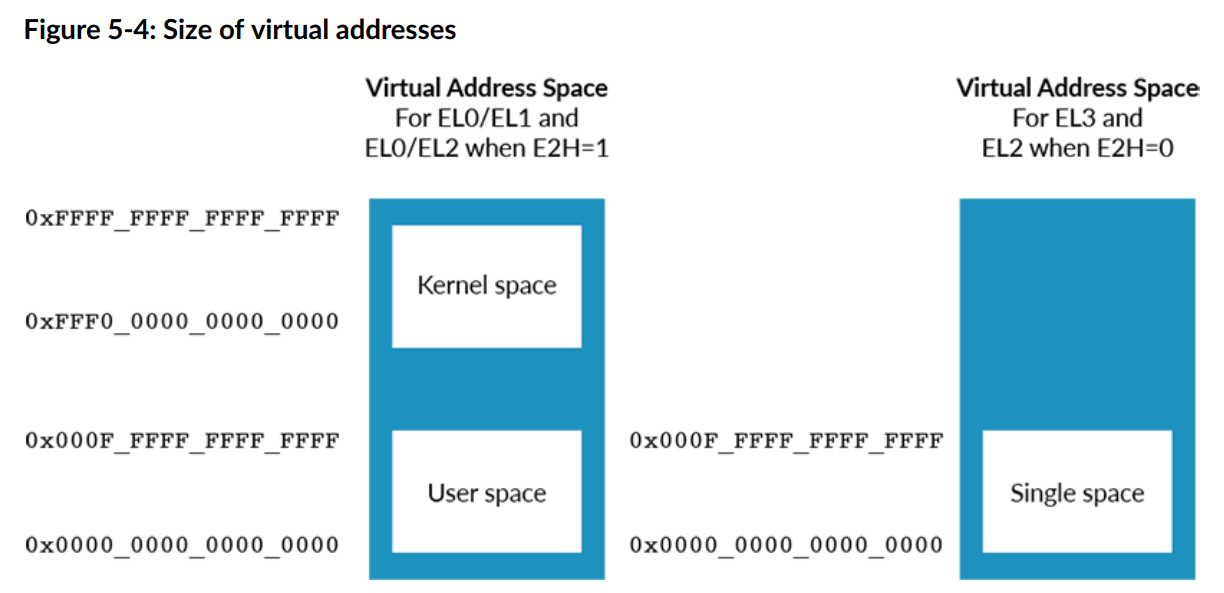
EL0/EL1 虚拟地址空间有两个区域:内核空间和应用程序空间。这两个区域显示在关系图的左侧,内核空间位于顶部,应用程序空间(标记为“用户空间”)位于地址空间的底部。内核空间和用户空间具有单独的转换表,这意味着它们的映射可以保持独立。
独立很重要,独立表明这两个东西不会相互影响。简单来说,当应用程序出现重大错误的时候,不会影响内核系统的运行,系统不会受到太大的影响。
空间标识符
现代操作系统的应用程序似乎都从同一地址区域运行,这就是我们所描述的用户空间。在实践中,不同的应用程序需要不同的映射。这意味着,例如,VA 0x8000 的转换取决于当前正在运行的应用程序。
理想情况下,我们希望不同应用程序在TLB 中共存,在 Armv8-A 中,通过地址空间标识符 (ASID)来进行管理。
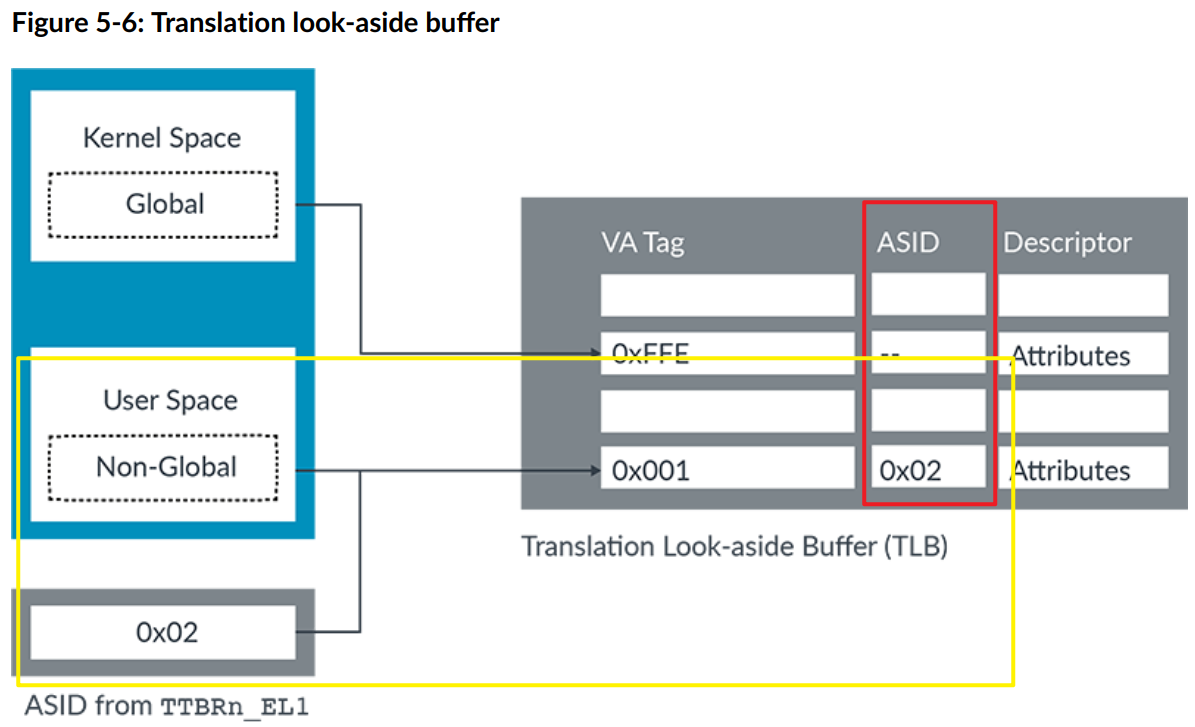
对于 EL0/EL1 虚拟地址空间,可以使用转换表条目的属性字段中的 nG 位将转换标记为全局 (G) 或非全局 (nG)。例如,内核映射是全局转换,而应用程序映射是非全局转换。全局翻译适用于当前正在运行的任何应用程序。非全局翻译仅适用于特定应用程序。
非全局映射在 TLB 中用 ASID 进行标记。在 TLB 查找中,会将 TLB 条目中的 ASID 与当前选定的 ASID 进行比较。如果它们不匹配,则不使用 TLB 条目。下图显示了内核空间中没有 ASID 标记的全局映射和用户空间中具有 ASID 标记的非全局映射:
小结
本文仅仅是简要介绍了 MMU 和 TLB,对 MMU 的意义、组成有一定的了解就好。接下来再阅读 ARM 的架构书,补充一些 MMU 具体的内容。